如题例如抓取这个文章下的所有评论:链接。首先,列出需要抓取的数据:
- 新闻标题
- 新闻发布日期
- 评论者的昵称
- 评论的内容
分析网页请求找到需要的数据
看下图,在网页的第一个请求里面已经包括了1,2两条的数据。
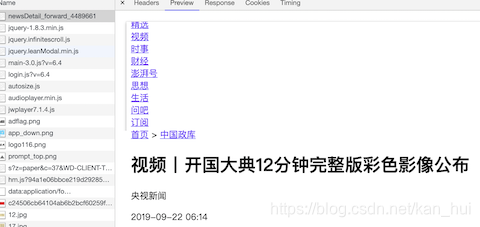
接着在浏览器中向下滑动新闻网页加载评论,同时关注控制台,注意搜索框里的load,如下图浏览器会不断的发送请求给服务器,在这个请求的相应里面就包含了需要的3,4条(评论,评论者的用户名)数据。看一下这个请求的url有一堆的请求参数尝试精简下最后得到这样的urlhttps://www.thepaper.cn/load_moreFloorComment.jsp?contid=4489661startId=24750775。在这个url里面只有两个参数,第一个是新闻的id,第二是评论页的id。有了这个url就可以根据不同的startid构造出评论的url最终的抓到所有的评论信息。
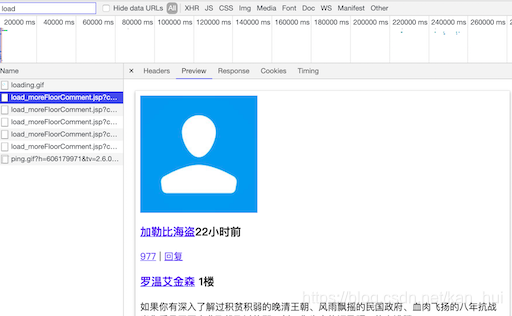
怎么找到不同的startid?
同样是上面那个图,在新标签打开对应的请求,看一下html源码,在第一条评论div里面有一个startid=’24745735’。
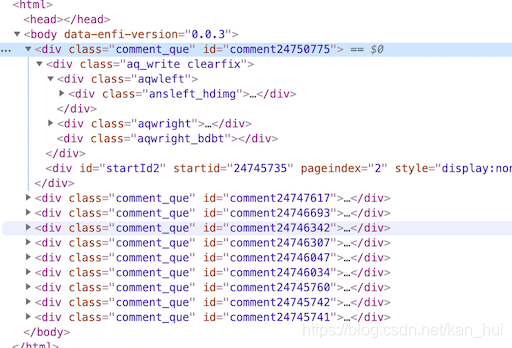
记住这个值,再回去看一下第二条请求评论的url,发现最后的startid值就是第一条请求评论的url里面的startid值。就是这个样子:
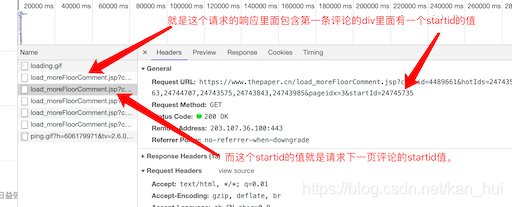
至此,所有的数据理论上来说都可以找到了。剩下的就是写代码了。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
import requests
import re
from lxml import etree
import json
class PengPaiSpider():
'''
给定一个澎湃新闻的url爬取其下的评论信息
例如:https://www.thepaper.cn/newsDetail_forward_1292455
'''
def __init__(self):
print('input url:')
self.url = input()
self.next_id = ''
self.item = {}
self.header = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
self.contid = re.findall(r'forward_(\d*)', self.url)[0] if len(
re.findall(r'forward_(\d*)', self.url)) is not 0 else 0
self.comment_url = 'https://www.thepaper.cn/load_moreFloorComment.jsp?contid={}&startId={}'
if self.contid == 0:
print('获取contid失败,检查url!!')
def parse(self, url):
'''发送请求函数'''
res = requests.get(url)
print(url)
return res.text
def start(self):
self.get_new_data()
while self.next_id is not 0:
res = self.parse(self.comment_url.format(self.contid,self.next_id))
self.handle(res)
self.save_comment()
def handle(self, res):
root = etree.HTML(res)
comments = root.xpath(
"//div[@class='comment_que']//div[@class='ansright_cont']/a/text()"
)
usernames = root.xpath('.//h3/a/text()')
self.item = [{
'Nickname': username,
'content': comment
} for username, comment in zip(usernames, comments)]
new_next_id = int(re.findall(r'startId="(.*?)"', res)[0])
if self.next_id == new_next_id:
self.next_id = new_next_id - 14
else:
self.next_id = new_next_id
def get_new_data(self):
'''用来获取新闻的信息'''
res = self.parse(self.url)
root = etree.HTML(res)
self.item['链接'] = self.url
tmp = root.xpath("//h1[@class='news_title']/text()")
self.item['标题'] = tmp[0] if len(tmp) is not 0 else ''
tmp = root.xpath("//h2[@id='comm_span']/span/text()")
if len(tmp) is not 0:
self.comment_count = re.findall(r'\((.*)\)', tmp[0])[0]
if self.comment_count.isdigit():
self.item['评论数'] = self.comment_count
else:
self.comment_count = float(self.comment_count[:-1]) * 1000
self.item['评论数'] = self.comment_count
tmp = root.xpath('//div[@class="news_about"]/p/text()')
if len(tmp) == 3:
post_time = re.findall(r'(\d{4}-\d{2}-\d{2})', tmp[1])[0] if len(
re.findall(r'(\d{4}-\d{2}-\d{2})', tmp[1])) is not 0 else ''
self.item['时间'] = post_time
self.save_comment()
def save_comment(self):
with open(self.contid + '.json', 'a') as f:
f.write(json.dumps(self.item, ensure_ascii=False, indent=4))
if __name__ == '__main__':
my_spider = PengPaiSpider()
my_spider.start()
print('完成!')
|
